放置Apple的AI报告更深入的报道:记忆的使用率为
- 编辑:admin -放置Apple的AI报告更深入的报道:记忆的使用率为
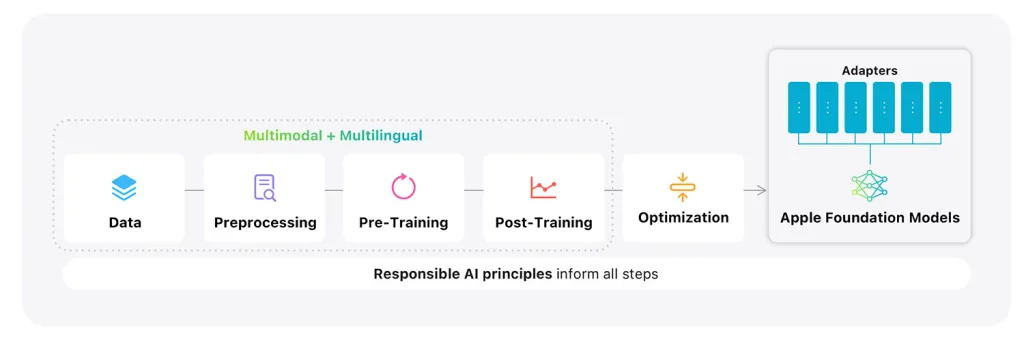 7月22日的新闻,技术媒体9to5MAC昨天(7月21日)发表了一篇博客文章,以探讨新的Apple技术报告,探索AI模型的培训,优化和评估过程,并揭示了现场的许多技术细节。该报告的全名是“ Apple Intelligence Foundation Foundation Models Models Report 2025.”。它详细介绍了AI的多个方面的Apple管理,涵盖了模型,数据源,预训练,工具开发,优化测量和性能参考点的体系结构。媒体解释了技术报告,并发掘了值得关注的四个关键点:Endanese模型的双重块设计。以前的消息表明,苹果的模型采用了Endrese +云组合方法,表明endrey模型量表约为参数的30亿(3B)。根据最新的技术报告,苹果的横向模型分为两个块,而FIR分为包含大约62.5%的变压器层的ST块和包含大约37.5%变压器层的第二个块,但键值映射将被删除。苹果说,这种细分方法在存储在高速缓存中时会减少模型的内存需求,而不会影响模型的一般性能和质量,并且还将产生第一个令牌的时间减少了37.5%。云模型对服务器端模型使用创新的体系结构。苹果公司已经开发了一种专门针对称为专家Mix(PT-MOE)的私有云计算平台的体系结构。简而言之,混合专家模式意味着而不是信任单个大型模型,而是将其分为多个子网(或专家)小Q,当任务与体验相关时,只有当时才有活跃。因此,如果输入消息与厨房有关,则只有厨房专家会活跃,而其他厨房专家将保持不活跃。因此,整个模型仍然很大,bUT它的模块化设计使该模型可以更快,更精确地响应。苹果公司构建了一个名为Parallel Track Transformer的新变压器,并使用混合专家(MOE)层扩展了它。听起来可能很复杂,但关键是传统的变压器模型反过来通过层电池进行处理,而Apple Design将模型分为多个平行轨道。每个轨道都独立处理令牌,并在特定点同步。在每个轨道中,Apple负责由MOE层代替的每个曲目的正常变压器层,并且仅由标签激活,只有少数专家是ActiveBy标签,而其他专家则保持不活跃。每辆卡车都有自己的本地专家,因此该型号在整个系统中都可以防止瓶颈的处理。连同智能设计平衡本地环境和一般理解(称为全球和本地注意力层),它形成了模块化,高效且可扩展的模型,它是FA在保持高智力的同时,Ster和更快。苹果大大改善了多语言支持。当Apple Smart首次推出(并且仍然存在)时,最受批评的问题之一是其对英语以外的语言的支持有限。随着新模型的推出,苹果扩大了语言支持的范围和详细的步骤,以在其报告中实现这一目标。该报告说,苹果将培训期间使用的外语数量从8%增加到30%。苹果还将得分规模提高了50%。这意味着该模型现在可以识别150k不同的标记,而100K之前的标记。数据收集也与数据收集有关。您可以看到由此发表的博客文章。苹果在最近发表的研究工作中说,如果编辑不同意未对数据进行培训,那么苹果就不会分会数据。使用多样化和高质量的数据训练他们的模型。我认为应该完成。这些数据包括HA已从编辑器授权,来自Applebot Web Tracker跟踪的公开可用或开源数据以及公共信息的数据。
7月22日的新闻,技术媒体9to5MAC昨天(7月21日)发表了一篇博客文章,以探讨新的Apple技术报告,探索AI模型的培训,优化和评估过程,并揭示了现场的许多技术细节。该报告的全名是“ Apple Intelligence Foundation Foundation Models Models Report 2025.”。它详细介绍了AI的多个方面的Apple管理,涵盖了模型,数据源,预训练,工具开发,优化测量和性能参考点的体系结构。媒体解释了技术报告,并发掘了值得关注的四个关键点:Endanese模型的双重块设计。以前的消息表明,苹果的模型采用了Endrese +云组合方法,表明endrey模型量表约为参数的30亿(3B)。根据最新的技术报告,苹果的横向模型分为两个块,而FIR分为包含大约62.5%的变压器层的ST块和包含大约37.5%变压器层的第二个块,但键值映射将被删除。苹果说,这种细分方法在存储在高速缓存中时会减少模型的内存需求,而不会影响模型的一般性能和质量,并且还将产生第一个令牌的时间减少了37.5%。云模型对服务器端模型使用创新的体系结构。苹果公司已经开发了一种专门针对称为专家Mix(PT-MOE)的私有云计算平台的体系结构。简而言之,混合专家模式意味着而不是信任单个大型模型,而是将其分为多个子网(或专家)小Q,当任务与体验相关时,只有当时才有活跃。因此,如果输入消息与厨房有关,则只有厨房专家会活跃,而其他厨房专家将保持不活跃。因此,整个模型仍然很大,bUT它的模块化设计使该模型可以更快,更精确地响应。苹果公司构建了一个名为Parallel Track Transformer的新变压器,并使用混合专家(MOE)层扩展了它。听起来可能很复杂,但关键是传统的变压器模型反过来通过层电池进行处理,而Apple Design将模型分为多个平行轨道。每个轨道都独立处理令牌,并在特定点同步。在每个轨道中,Apple负责由MOE层代替的每个曲目的正常变压器层,并且仅由标签激活,只有少数专家是ActiveBy标签,而其他专家则保持不活跃。每辆卡车都有自己的本地专家,因此该型号在整个系统中都可以防止瓶颈的处理。连同智能设计平衡本地环境和一般理解(称为全球和本地注意力层),它形成了模块化,高效且可扩展的模型,它是FA在保持高智力的同时,Ster和更快。苹果大大改善了多语言支持。当Apple Smart首次推出(并且仍然存在)时,最受批评的问题之一是其对英语以外的语言的支持有限。随着新模型的推出,苹果扩大了语言支持的范围和详细的步骤,以在其报告中实现这一目标。该报告说,苹果将培训期间使用的外语数量从8%增加到30%。苹果还将得分规模提高了50%。这意味着该模型现在可以识别150k不同的标记,而100K之前的标记。数据收集也与数据收集有关。您可以看到由此发表的博客文章。苹果在最近发表的研究工作中说,如果编辑不同意未对数据进行培训,那么苹果就不会分会数据。使用多样化和高质量的数据训练他们的模型。我认为应该完成。这些数据包括HA已从编辑器授权,来自Applebot Web Tracker跟踪的公开可用或开源数据以及公共信息的数据。
